AI Marketing
The role of artificial intelligence in marketing
AI is transforming the way marketers connect with their audiences. In this article, explore how technologies like natural language processing and machine learning are powering smarter, faster strategies that fuel growth. Plus, grab a practical toolkit to help your brand navigate—and lead—this AI-driven shift.
Reading time 9 minutes
Published on May 7, 2026
Table of Contents
Summary
- AI marketing transforms strategies with technologies like natural language processing, machine learning and sentiment analysis for precise customer insights and trend forecasting.
- AI tools streamline social media listening by quickly extracting key details from large data sets, helping marketers gauge customer sentiment and predict future actions.
- AI platforms analyze customer data to tailor content, producing engaging posts and personalized campaigns that boost brand engagement and market share.
The only constant in life is change. And the world of marketing is going through a tremendous change right now. Artificial intelligence (AI) marketing is taking on a bigger role with the advent of intelligent marketing tools and generative AI like ChatGPT, creating an abundance of opportunities for marketing teams to do more of what they already do best. As marketers, this is an essential advantage.
AI marketing combines AI technologies with customer and brand experience data to provide highly precise insights into your customer journey and market trends. AI technologies like natural language processing (NLP), machine learning (ML), sentiment analysis and others guide decision-making, so you stay ahead of competitors and are prepared for the challenges of a dynamic marketplace.
So, let’s dive into the nuts and bolts of how AI is benefiting marketers and how you can use it to your full advantage.

Try a Demo of Sprout Social's AI and Automation Tools
How is artificial intelligence used in marketing?
AI-driven marketing is set to drive 45% of the total global economy by 2030. It’s poised to do so in several ways such as data-driven product enhancements, personalized services and influencing consumer demand.
Here is a closer look.
Social media listening
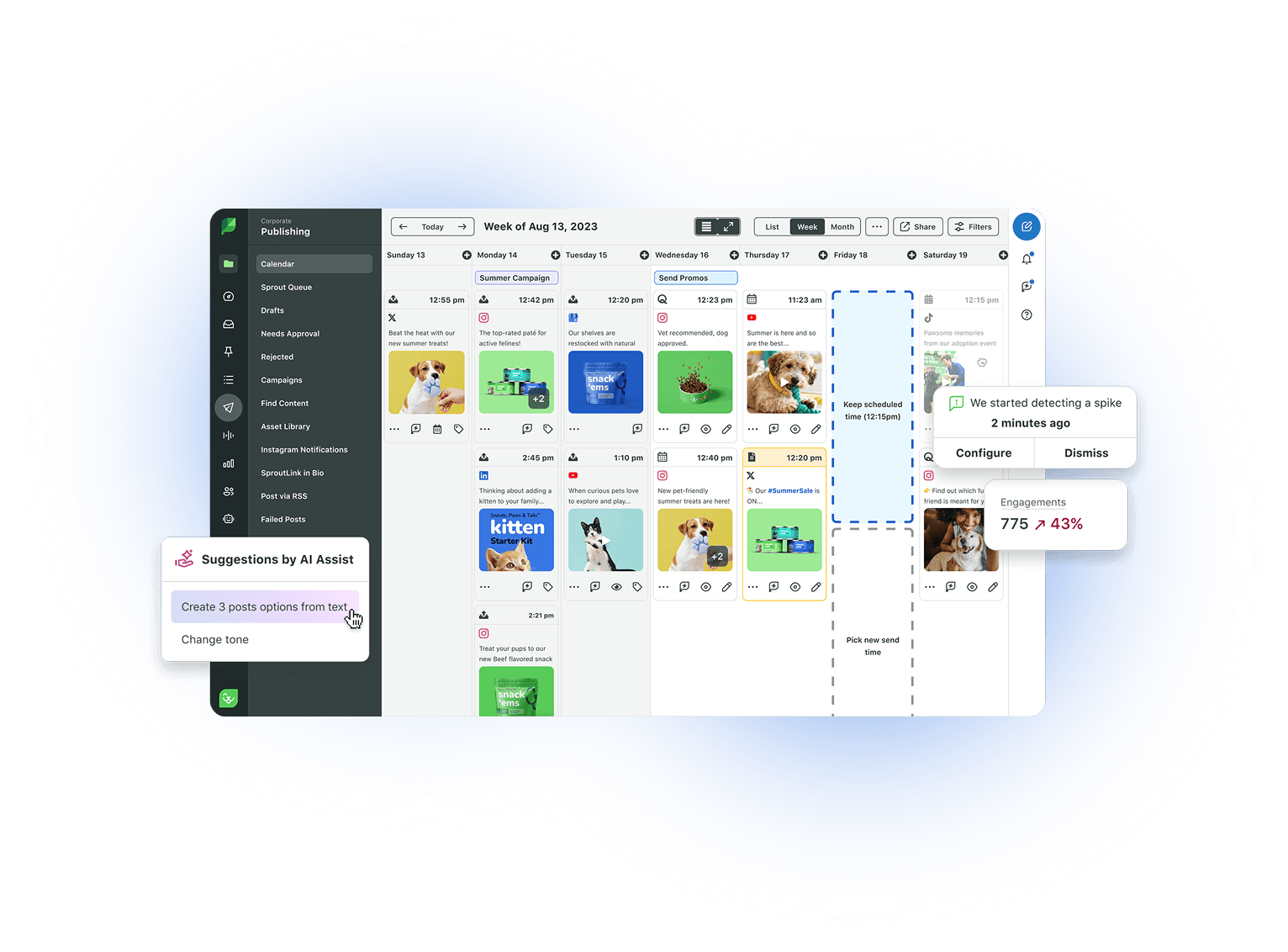
When social marketing is powered by AI, it increases your efficiency by taking social listening to a whole new level. For example, Sprout’s upcoming Queries by AI Assist feature will use OpenAI’s GPT model to serve up a vast range of suggested terms to include in your tracking, helping marketers discover essential audience insights faster.
AI algorithms use aspect-clustering to identify and extract relevant details from social listening data that can span millions of data points in real time. They help you cut through the noise and gain a deep understanding of the customer’s mind through social media sentiment analysis. This allows you to anticipate your customers’ next move and take strategic actions for intended results.
Bonus Resource: Get our top five AI social media marketing resources in one convenient toolkit. Download it for customizable templates and tips to drive smart AI adoption in your role and across your organization.
Content generation
Intelligent social media management tools, like Sprout, analyze voice of customer (VoC) data in social posts and reviews to inform what content your target audience is most interested in. Check out how the Atlanta Hawks use Sprout’s Tagging feature for this very purpose.
AI-powered platforms also identify keywords and triggers to help you develop compelling posts, respond better to customer comments and inspire more impactful product descriptions for your website. All these add to your efforts toward brand engagement for an increase in market share and improved earnings.
AI-generated ideas can also make your nurture campaigns more successful. They help you create compelling communications to reinforce relationships with prospects at each level of the sales funnel. AI prompts can help you develop email subject lines that get better open rates, develop personalized content adapted to buyer personas, drive conversations based on intent and engage with each prospect/client individually. This leads to stronger connections and loyalty that stimulate your sales.
Automation
AI-driven smart automation empowers social media managers and customer service teams to improve operational efficiency through lexical and statistical-based triggers that drive intelligent workflows.
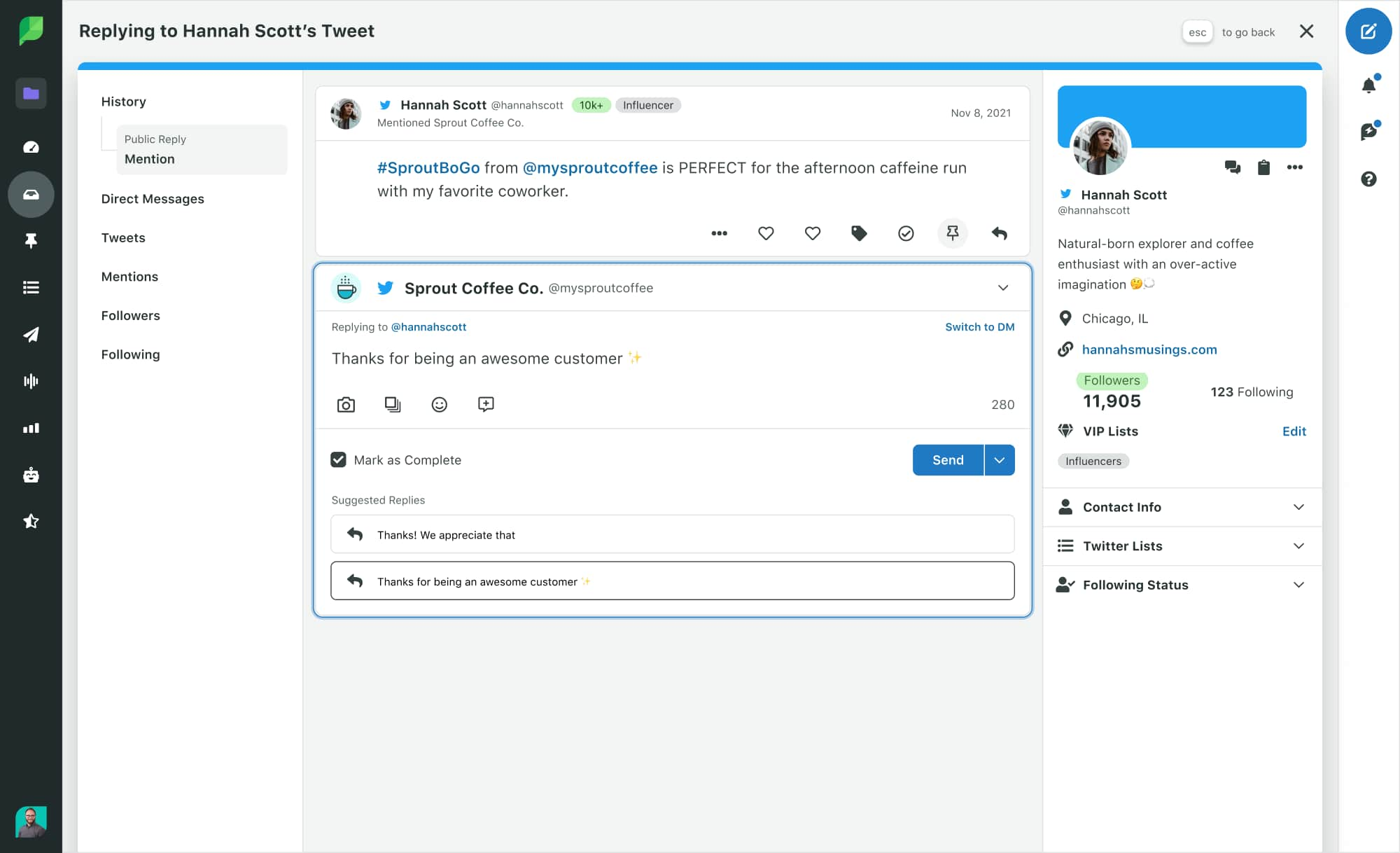
It helps you achieve business goals efficiently by taking the guesswork out of tasks, such as scheduling posts at optimal times for the greatest impact or categorizing incoming messages. It also enables a unified brand voice in customer communications and cuts response time in half through rules-based features, like our Suggested Replies.
Audience segmentation and personalization
AI marketing can drive your omnichannel business strategies based on market segmentation, aligning your campaigns with customers who are most likely to buy your product or offering.
You can also leverage programmatic advertising to streamline the process of selecting and setting up digital ads for the most return on investment (ROI). This enables more personalized marketing tactics to nurture brand loyalty and create powerful brand awareness campaigns.
Data analysis for customer insights
AI and machine learning give critical customer insights on a range of aspects to help you make strategic marketing decisions. Get deep insights into audience sentiment around your brand, and a full audit of your customer care team’s performance and social media engagement metrics.
This can empower you to quickly adapt to changing market trends, prioritize budgets based on what aspects need the most investment and deepen customer relationships.
Reputation management
When it comes to brand reputation, let’s be honest, there are some things in your control, while some just aren’t. Social media has made brands more susceptible to scrutiny than ever before. But with AI-enabled brand reputation management, you can avert a potential brand threat before it turns into a big issue.
Monitoring negative sentiments in real-time, choosing the right influencers and ambassadors and providing proactive customer care–all this can be achieved seamlessly with AI marketing tools.
Competitive intelligence
AI tools can help you spot opportunities to improve your products and offerings, and fill market gaps. Discern your competitors’ share of voice and find smart ways to be agile in a competitive market. Also, compare your social performance to your competitors via competitive benchmarking. This enables you to maneuver your strategy accordingly or adjust your benchmarks, so you maintain a competitive edge.
Multilingual advantage
A global presence must take into account cross-cultural elements along with providing prompt and efficient customer care. AI marketing tools can extract customer insights from multilingual data effortlessly so you know which strategy will likely be the most successful in a particular geography. You can also ensure your intended audience finds your social posts, responses and advertisements relatable and adhering to their cultural standards.
Which AI technologies enable marketing?
Powerful social marketing platforms, like Sprout, weave together sophisticated AI technologies under the hood to provide the insights you need to succeed. Capabilities such as semantic classification, named entity recognition and aspect based sentiment analysis help you get targeted insights specific to your industry, while natural language processing helps you optimize social content and improve customer engagement—all leading to greater competitive advantage and share of voice.
Let’s get to know these technologies better.
1. Machine learning
Machine learning (ML) uses statistical methods to analyze social data for high-precision insights around customer experience, audience sentiment and other marketing drivers. Once trained, ML models automatically complete text mining, topic extraction, aspect classification, semantic clustering and other tasks to provide results in seconds.
AI-ML models get smarter as they process more data over time and so upgrade automatically, which is perfect for scaling your business operations while minimizing future investment in your tech stack.
2. Natural language processing (NLP)
Natural language processing powers your AI marketing tool so it can semantically and contextually understand social listening data. It combines rules-based lexical and statistical methods, enabling you to scan a wide range of posts, messages, reviews or comments and extract critical information from it.
When NLP algorithms are coded for social listening, they can interpret the data even if it’s splattered with colloquialisms, code switches, emojis, abbreviations, hashtags or spelling mistakes. Natural language generation (NLG) further enhances the tool’s capabilities to help you create high-performing copy for posts, customer responses and more.
This gives you access to a wider audience for outreach campaigns, stronger communication with existing customers and better returns on our investment in social.
3. Semantic search
Semantic search algorithms are critical in NLP because they help understand the intent of a phrase or lexical string without depending on keywords. These algorithms extract relevant keywords and categorize them into semantic clusters. This eliminates chances of duplicates in text mining, especially where sentiment analysis is concerned, for an accurate measure of customer experience or brand performance.
Knowing exactly how strong your brand is in relation to your competitors and monitoring it against your benchmarks can help you alter marketing and sales strategies to achieve long-term business goals.
4. Named entity recognition (NER) and neural networks
NER helps an AI platform identify named entities in big data. These entities could be important people, places or things such as CEOs, celebrities, locations, currencies, businesses and others. It can identify these entities even if they are misspelled. NER also is a key function in generating knowledge graphs because they establish a relationship between entities in order to derive context and insights from data.
Neural network (NN) algorithms, built to mimic how a human brain handles information, remember these interconnected data points and keep adding them to their knowledge database. This is what enables ML models to provide more precise results with time through deep learning.
Thus, you get to know why certain brands keep appearing in your social listening data, what new market trends are brewing, which influencers would be a great fit and many other insights that can help you strengthen your social marketing strategy.
5. Sentiment analysis
Sentiment analysis is the process of measuring customer sentiment from feedback data and can be instrumental in helping with reputation management. Sentiment analysis algorithms analyze social listening data including survey responses, online reviews and incoming messages, both in real-time and historically. They measure sentiment in every aspect that is extracted from the data and assign polarity scores in the range of -1 to +1. Neutral statements are counted as zero.
When analyzing social data where customers are talking about aspects of a business, sentiment analysis models consider the polarity score of each aspect. These sentiment scores are aggregated to provide an overall sentiment of the brand in terms of customer experience. This eventually gives you an idea of how well your business is performing.
With such insights available, you can grow your brand by evaluating and improvising social media content, shaping sales and marketing, improving brand management, better interpreting customer intent and so much more.
What is the future of AI in marketing?
AI marketing is achieving new advancements at a phenomenal speed. Here are some ways it’s reshaping businesses for the better.
Computer vision
Computer vision allows AI marketing tools to derive insights from non-text digital data available in the form of raw images. From powering optical character recognition (OCR) to analyze information and signatures in checks and recognize brand logos in videos, to extracting text from images for accessibly, computer vision is helping solve key business challenges every day.
In retail, computer vision can be used to identify imperfections in products in a manufacturing assembly line or to ensure shelves are always full. It also helps in improving biometric authentication with enhanced facial recognition to identify shoplifters, a customer or employee in distress and so much more.
AI chatbots
Conversational AI in the form of virtual agents and intelligent chatbots is set to change traditional marketing. AI chatbot marketing can put brand visibility in hyperdrive with targeted messaging.
As these conversational interfaces evolve into more sophisticated business tools, brands are increasingly looking into how to create AI agents that can handle cross-functional requests beyond basic customer support.
They can boost engagement with existing customers and prospects to generate leads and also analyze their data to provide you with fine-grained insights for predictive and prescriptive marketing.
Virtual agents also streamline customer requests, ensure 24/7 customer support and route conversations to the appropriate team for the best results–all resulting in increased customer satisfaction and loyalty.
Predictive and prescriptive AI
Predictive and prescriptive analytics are already making AI marketing tools essential for marketers. Prescription analytics sorts social listening data into categories based on consumer motivations, mindsets and intentions. This information from conversational analytics enables you to develop highly targeted ads, posts and emails that will yield optimal results. A great example of this is how streaming services use your previous choices to provide you with content relevant to your interests.
Predictive analytics enables you to go further so you can anticipate outcomes and develop a business strategy well in advance based on past voice of customer data. This means you can build long-term business models, conduct risk evaluations, expand market acquisitions, improve product designs and more.
Responsible AI
AI marketing also takes into account the fact that existing AI models are not perfect. To achieve true advantages and accuracy in deriving business insights, AI in business needs to be fair, secure, reliable, inclusive and transparent. This means that AI tools need to be developed more thoughtfully and trained with diverse data to remove biases.
There are also data privacy, copyright and governance rules being developed to ensure that ethical and societal implications are considered in order to be fair to humans and AI development companies. This means social networks and social marketing teams need to be cognizant of how they employ AI tools to collect customer data, create content, show personalized ads to influence purchase behavior or for any other reason.
Build impactful business strategies with AI
AI marketing strategies and insights are empowering businesses to build a foundation for growth and future success by exploring new marketing, product and customer engagement opportunities. AI technologies like sentiment analysis, NLP, virtual agents and others are determining how efficiently you reach business goals, from revenue optimization to navigating unpredictable market scenarios.
With targeted AI-driven customer insights you can develop a more proactive social media marketing approach to drive customer engagement, loyalty and retention. And ultimately market growth.
Read how investing in AI can help you build a stronger, more robust business strategy.
Additional resources for AI Marketing

Designing an AI marketing strategy for social media: An expert guide
The role of artificial intelligence in marketing
AI in marketing examples and strategies you can use today

How to create AI agents for social media marketing
What are AI agents and why do marketers need them now

Why the best AI use cases in marketing start with intelligence, not creation


7 real-world examples of brands using Sprout Social AI to drive results

19 best social media AI tools to transform your social media strategy

25 best AI marketing tools for smarter workflows

The complete guide to chatbots for marketing

Marketing automation: The complete guide for your brand in 2026
Build smarter workflows with AI marketing automation

How to adopt AI for content marketing

How to use conversational AI to deliver personalized customer service at scale



How AI insights improve decision making

How to use AI analytics for targeted business decisions

How to craft an effective AI use policy for marketing

AI ethics: How marketers should embrace innovation responsibly

AI isn’t something business leaders can rush into

The role of AI in creating a more human customer experience
How AI is changing communications and PR: Risks and benefits

When AI is everywhere, invest where it counts