
Sentiment Analysis
How to use sentiment analysis to analyze customer opinion
Dive into the world of sentiment analysis to boost your brand strategy. Read about all its intricacies, types, challenges and transformative impact on customer engagement and loyalty.
Book a live demo today to see how sentiment analysis can transform your customer engagement strategy.
Reading time 15 minutes
Published on June 24, 2026
Table of Contents
Summary
- Sentiment analysis helps turns large volumes of customer feedback into social intelligence. It analyzes comments, reviews, surveys and customer care interactions to reveal how people feel about a brand, product or experience.
- These insights help brands understand customer perception, spot emerging trends and make more informed decisions across marketing, product and customer care.
- Sentiment analysis uses AI techniques such as natural language processing and machine learning to classify customer feedback as positive, negative or neutral. More advanced models can also detect sentiment by topic, feature or intent.
Customers tell brands how they feel every day through social comments, direct messages, reviews, surveys and support conversations. The challenge is that feedback is scattered across channels and often too large to review manually.
Sentiment analysis helps brands make sense of that feedback at scale. It processes large volumes of text, identifies emotional cues and surfaces patterns that show how customers feel about your brand, products, services and campaigns.
That makes it easier to answer questions like: How do customers feel about my brand right now? What complaints keep coming up? Which messages are landing? Are customers reacting positively to a launch, or is an issue starting to build?
Used well, sentiment analysis gives brands a clearer view of customer opinion, helping them respond faster, improve customer experiences and make smarter business decisions.
In this article, we’ll explore what sentiment analysis is, why it matters, how it works and how to use it to strengthen your brand strategy.
What is sentiment analysis?
Sentiment analysis is an AI technique for determining if customer opinions in text are positive, negative or neutral. This technology processes social media comments, reviews and messages to reveal how people feel about your brand, products or services in real-time.
Brands use sentiment analysis tools in AI marketing to surface insights from voice of customer (VoC) data across sources such as social listening, reviews, surveys, customer care interactions and direct messages. These insights help teams monitor brand health, improve products and increase customer engagement and retention.
Platforms like Sprout Social build sentiment analysis into social listening, care and reporting workflows, helping teams monitor customer conversations and turn feedback into actionable business insights.
Why sentiment analysis matters for brand growth
Customers tell brands exactly how they feel, constantly and across every channel. The challenge is tracking and translating all that feedback into usable insights.
Sentiment analysis solves it, reading millions of comments, reviews and messages in seconds and labeling the emotion behind each one. This process helps brands catch emerging trends and potential crises early, understand audiences across languages and markets and measure campaign performance while it’s still live.
Strong sentiment analysis feeds the decisions that grow a brand: what to build, what to say and how to serve customers better. Here’s what a brand can achieve with sentiment analysis.
Ready to decode the sentiment in your direct messages and online reviews?
Try Sprout’s Advanced Plan free for 30 days
Understand customer perception in real time
Customers form opinions quickly, especially on social. Real-time sentiment analysis gives brands a clearer read on those reactions while conversations are still unfolding. Instead of waiting for a monthly report or reading comments one by one, teams can monitor shifts across social posts, reviews, direct messages and customer care conversations.
Machine learning adds consistency at scale. It applies the same criteria to reviews, social posts, support messages and survey responses, making it easier to compare sentiment across channels and spot patterns over time.
It doesn’t replace human judgment. Teams still need context to understand sarcasm, nuance and sensitive issues. But it gives them a more reliable starting point than manual review alone.

Identify brand risks before they escalate
A sharp rise in negative sentiment can be an early warning sign. It may point to a product issue, a service disruption, a policy change or a public conversation that needs attention.
By tracking changes as they happen, teams can see when negative feedback is building, where it’s happening and which topics are driving the shift. That gives brands a chance to investigate and respond before a small issue becomes a larger reputation risk.
Turn customer feedback into marketing insights
Customer conversations are full of clues about what people value, question and complain about. Grouping those conversations into recurring themes helps you see which messages, topics and campaigns are resonating.
A word cloud can support this analysis by visualizing the keywords that appear most often within a topic. When combined with sentiment scores, it helps teams identify the language customers use and the ideas that appear most often.
The same data can sharpen campaign strategy. Track sentiment alongside campaign KPIs to see which messages connect, then adjust content while the campaign is still live.
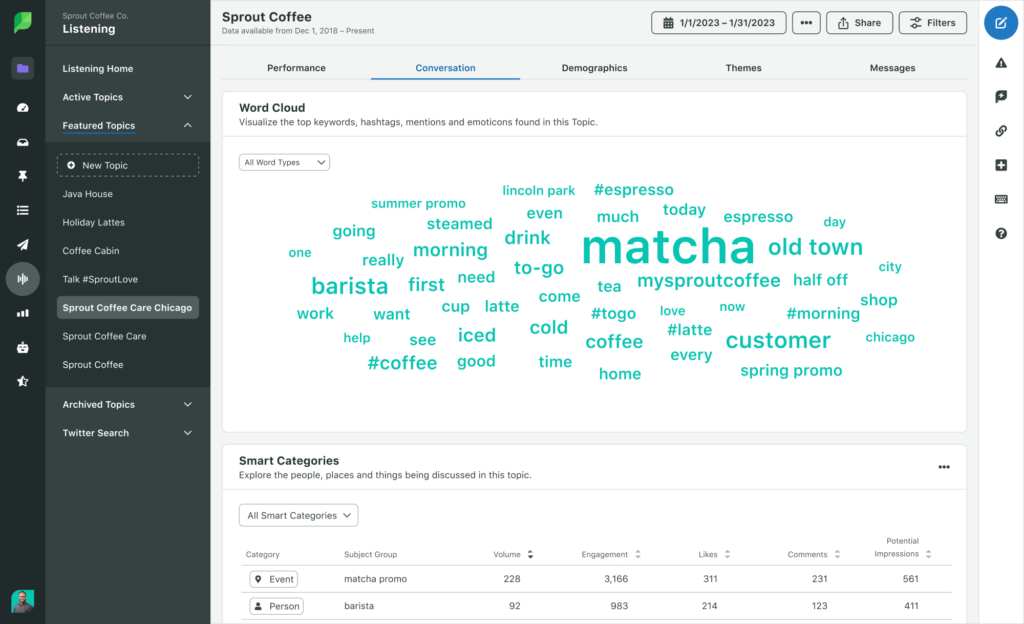
Improve customer experience across channels
Customers share feedback across many channels, languages and markets. Comparing sentiment across those touchpoints gives brands a clearer view of where the experience is working and where it may be breaking down.
For example, negative sentiment in reviews may point to a product issue, while recurring frustration in direct messages may reveal a support gap. Looking at sentiment by channel, region or customer segment helps teams decide where to focus their next improvement.
How does real-time sentiment analysis for social media help brands?
Real-time sentiment analysis helps brands understand customer reactions while a conversation is still active. Instead of reviewing feedback after a campaign ends or a crisis passes, teams can monitor sentiment as it changes and decide what to do next.
This is especially useful on social media, where customer expectations move quickly. According to the 2025 Sprout Social Index™, 73% of social media users expect brand responses within 24 hours. Monitoring sentiment in real time helps teams spot urgent issues, prioritize responses and understand how customers are reacting in the moment.
Real-time sentiment becomes even more valuable when it’s shared across the business as a part of social intelligence. Marketing can optimize campaigns based on how they are landing. Customer care can prioritize frustrated customers. Product teams can identify and address recurring issues. And leadership can get a clearer view of how customer perception is changing.
It also supports predictive media intelligence. When a story, trend or issue starts gaining traction, brands can monitor sentiment around the conversation to understand how it may land with their audience. That gives teams more time to respond, adjust messaging or prepare for a wider shift in public perception.
How AI and social listening tools analyze customer sentiment
AI and social listening tools analyze sentiment by collecting customer feedback, preparing the data, identifying meaning in the text and turning those findings into actionable reports.
Step 1: Data collection
Start with the channels where your audience is most active, such as social media comments, direct messages, reviews, surveys, support tickets, forums and news coverage. Make sure your sentiment analysis tool integrates with the networks and sources you plan to monitor.
The goal is to collect the data most relevant to your question, whether you’re tracking brand health, campaign performance, customer care or product feedback.
Steps 2: Data processing and sentiment mining
Once the data is collected, the tool cleans and organizes it by removing duplicates, filtering irrelevant mentions through noise filtration and grouping conversations by topic, source, keyword or brand mention.
AI models then analyze the language in each message to identify emotional cues and context. Using semantic search, more advanced tools can understand the meaning behind conversations and detect sentiment around specific topics or aspects. For example, a review may be positive about product quality but negative about shipping.
In Sprout Social’s Query Builder, the Exclude Noise option supports noise filtration by filtering out comments containing unwanted keywords and lets you set rulesets for themes such as customer service or product reviews. The tool then scores each topic and aspect to show what’s driving sentiment.
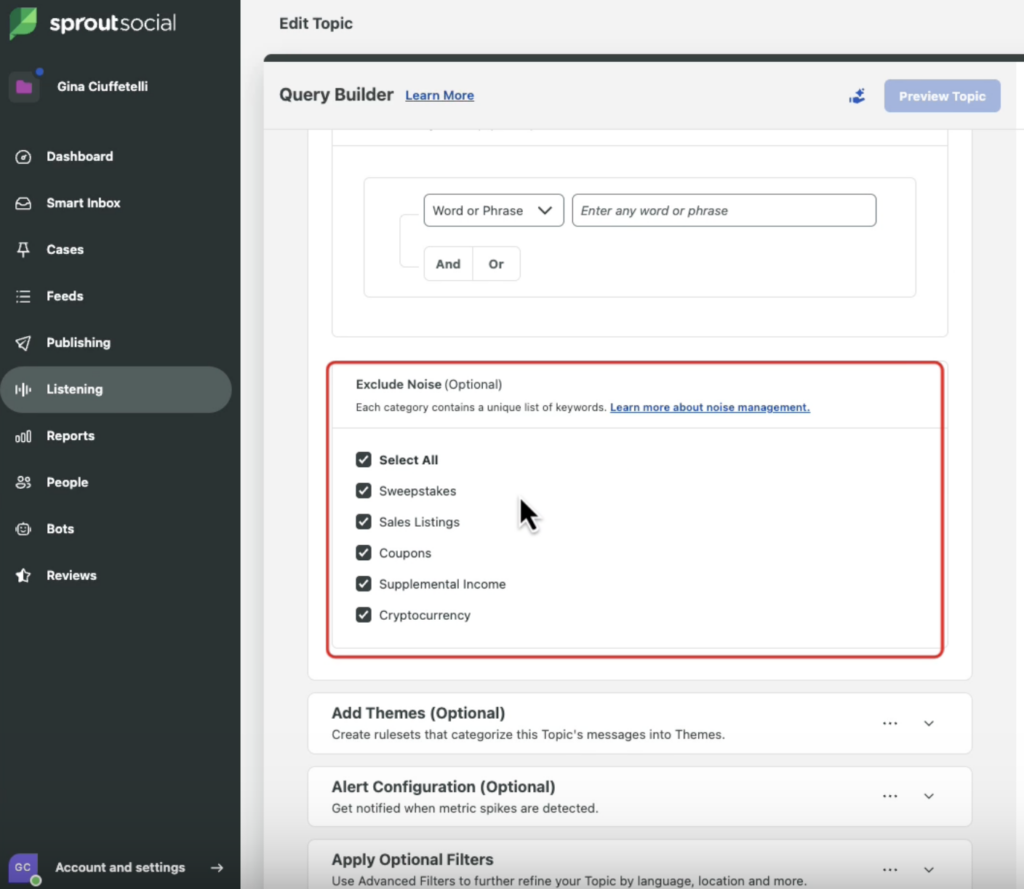
Step 3: Data visualization
Finally, sentiment tools turn the analyzed data into charts, graphs and reports. Teams can compare sentiment by platform, topic, keyword, data source, region and time period, then share those insights across marketing, customer care, product and leadership.
How does an AI tool calculate sentiment scores?
AI tools score sentiment by estimating how positive, negative or neutral a piece of text is. Basic lexicon-based methods count positive and negative words. More advanced AI models consider context, sentence structure and relationships between terms to better understand informal language, emojis, slang and implied sentiment.
Sprout’s model uses large language models built on Google’s BERT, which reads the full context of a comment in both directions. This helps classify text as positive, negative or neutral and estimate the probability of each result.
Which type of sentiment analysis is right for your business?
The three most common types of sentiment analysis are document-based, topic-based and aspect-based sentiment analysis (ABSA). They differ in precision, from a single score for an entire text to a detailed look at specific features such as price or service. Intent analysis often runs alongside them, reading what a customer wants to do rather than how they feel. The right mix depends on your goals.
| Type | Scope | Best Use Case | Complexity |
|---|---|---|---|
| Document-based | Entire document | Overall sentiment assessment | Basic |
| Topic-based | Specific topics/themes | Multi-topic content analysis | Intermediate |
| Aspect-based (ABSA) | Specific features/attributes | Detailed product feedback | Advanced |
| Intent analysis | Purpose behind a message | Routing sales and support | Advanced |
Document-based sentiment analysis for overall sentiment
Document-based sentiment analysis evaluates the overall sentiment of an entire document. Brands use this type to understand the general sentiment in individual comments, long-form articles and reports.
Topic-based sentiment analysis to understand customer reactions
Topic-level sentiment analysis is used to understand complex or scattered data. It breaks down sentences and paragraphs to identify recurring words and phrases and classifies them into topics, which it measures individually for sentiment.
When used to analyze customer comments on social media or review platforms, topic analysis helps you better understand the key points mentioned in the text, which you can then track.
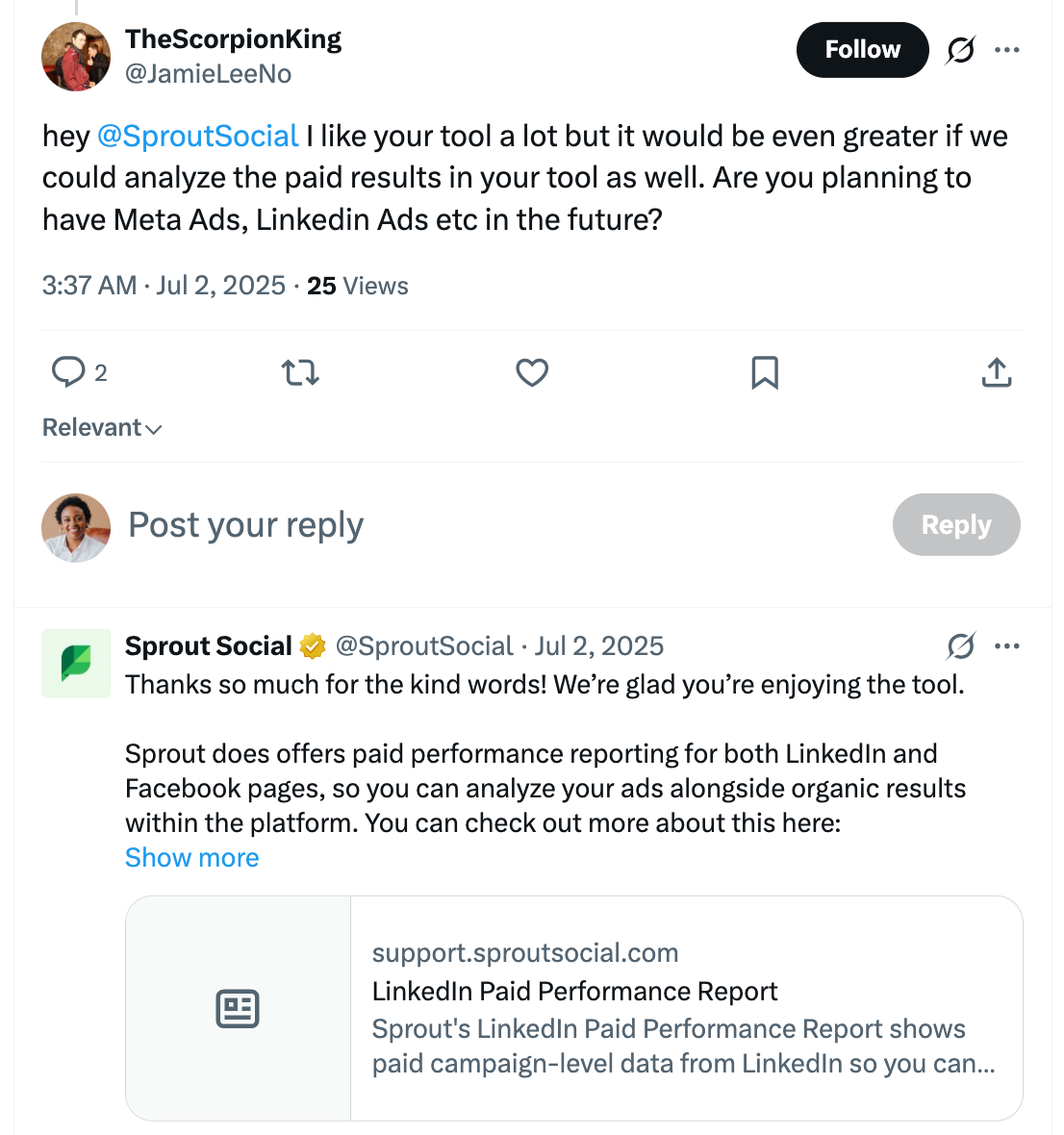
Aspect-based sentiment analysis for product and service insights
Aspect-based sentiment analysis (ABSA) is the most sophisticated of the three. It uses semantic classification to understand comments that don’t contain high-intensity positive or negative words, such as “love” or “hate,” to calculate sentiment. This also helps it understand the context necessary for accurate sentiment scores.
For example, this X post does not use any high-intensity sentiment words. Its tone is conversational, just someone saying an @Starbucks barista brightened their day. Advanced sentiment mining through ABSA breaks the sentence down, isolates the aspect (the barista) and reads cues like “makes your day a little brighter” and #goodvibes to identify the general sentiment (positive) to calculate its polarity.
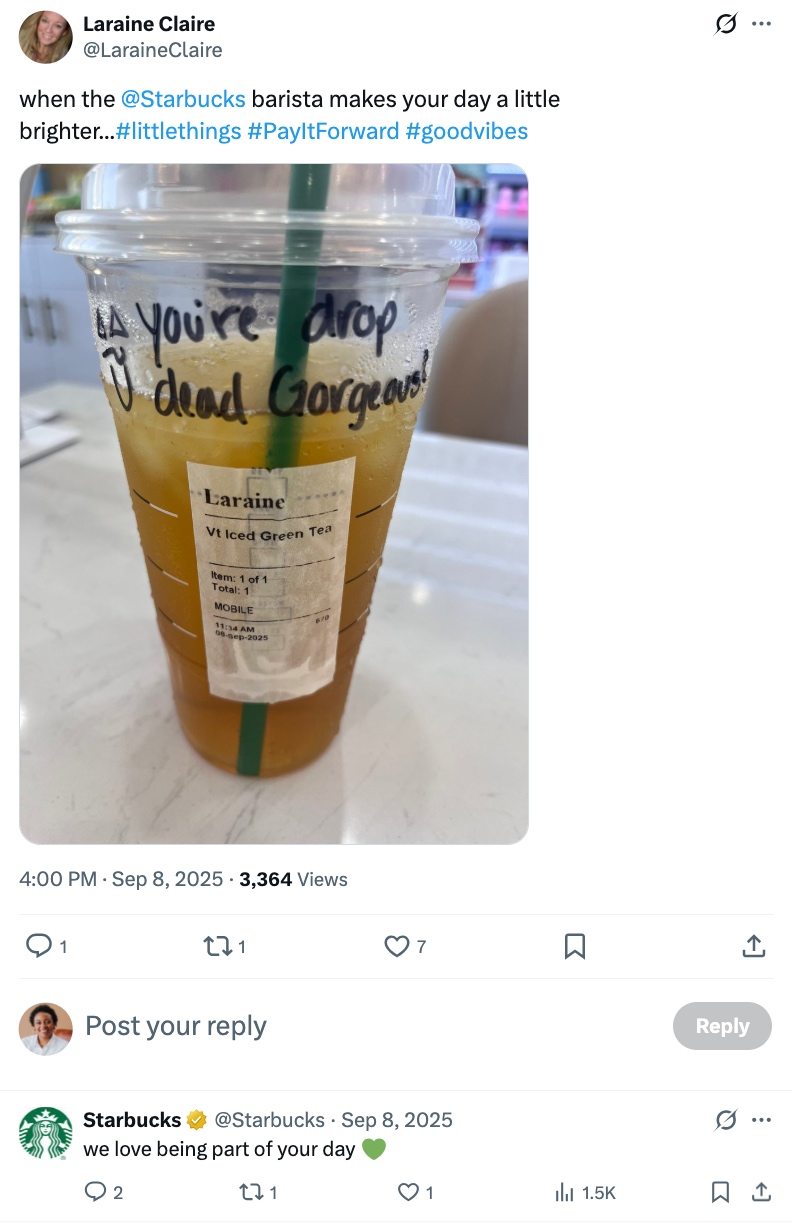
This advanced capability makes ABSA the preferred method to get the most accurate sentiment results, so brands can make informed decisions.
Intent analysis to uncover purchase and support signals
While the first three all measure sentiment, intent analysis is a natural companion, picking up the buying and support cues that sentiment alone misses.
- Purchase intent flags people who are comparing products, asking about pricing, or are close to buying, so sales steps in at the right moment.
- Support intent catches frustration or problems that need solving, so your care team gets to them first.
Pairing intent with sentiment turns a feed of opinions into a queue of actions: who to sell to, and who to help.
How brands use sentiment analysis to drive business decisions
With sentiment analysis, teams can move from “what are people saying?” to “what should we do next?” Brands use it to monitor customer perception, improve support, guide market research, protect reputation and create more relevant content.
Monitor brand sentiment across social media networks
Your brand gets talked about everywhere at once, across every social network and in the news. Monitoring sentiment across these sources gives you a more accurate picture of brand health and is an integral part of social intelligence.
AI-powered social listening tools can help by tracking conversations across platforms, analyzing sentiment at scale and flagging meaningful changes as they happen. More advanced agentic AI systems can go a step further by proactively surfacing trends, identifying potential risks and recommending areas for investigation based on evolving customer conversations.
Our real-time predictive media intelligence tool, NewsWhip, extends that monitoring to news and media coverage, helping teams understand how stories may influence brand perception beyond social.

Improve customer support with sentiment insights
Sentiment helps customer care teams prioritize the messages that need attention first. A frustrated customer, negative review or complaint about a recurring issue may need a faster response than a neutral mention or general comment.
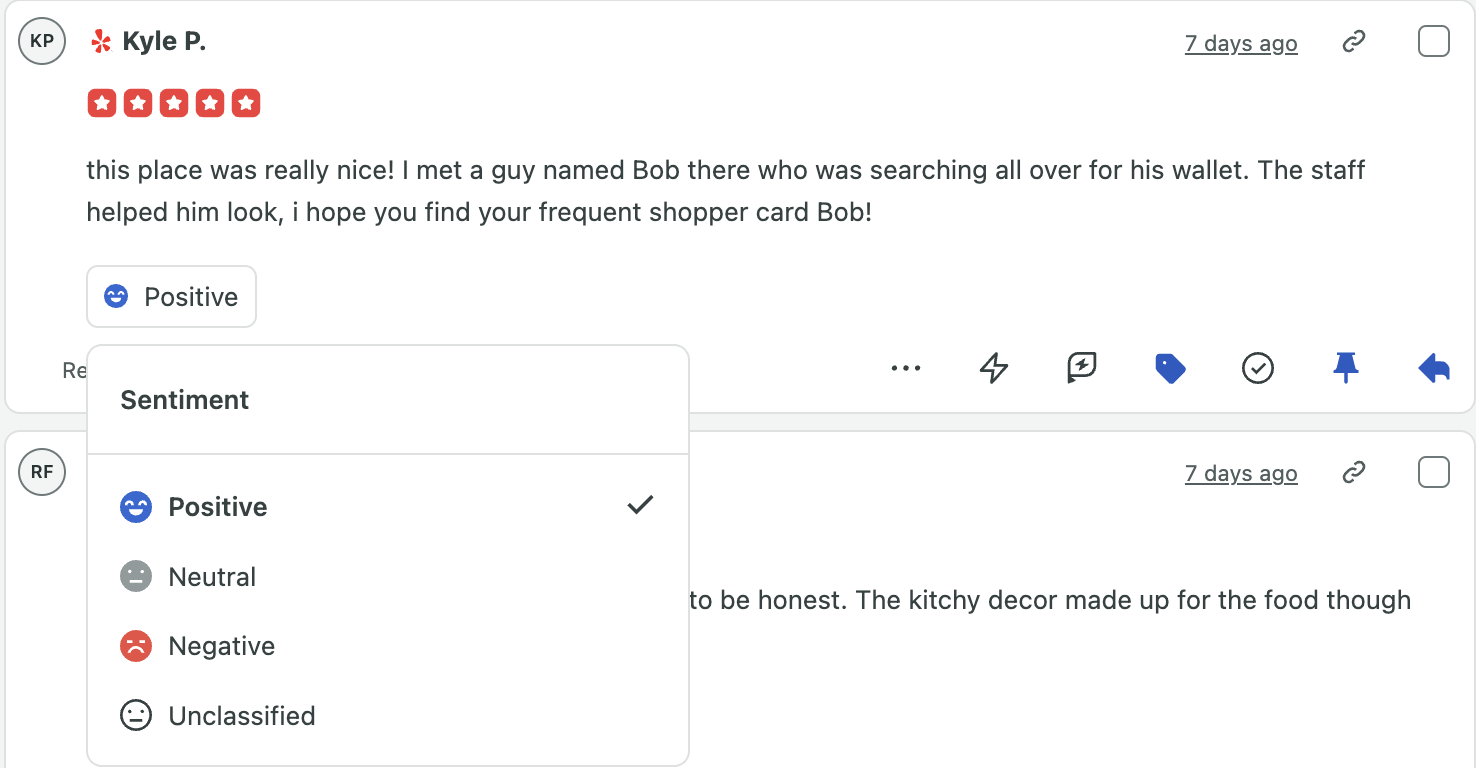
On Sprout’s Advanced Plan, AI sentiment analysis runs in the Smart Inbox and Reviews Feed, tagging each post positive, neutral, negative or unclassified. From there, Automated Rules route negative messages to senior team members and send positive mentions to your advocacy team.
Use customer sentiment to strengthen market research
Sentiment data can function as always-on market research. It shows how people feel right now about your category, your competitors and the needs that are not being met.
For example, recurring negative sentiment around a competitor’s pricing, support or product experience may reveal an opportunity to differentiate your brand. Positive sentiment around specific features or messages can show what customers already value and want to see more of.
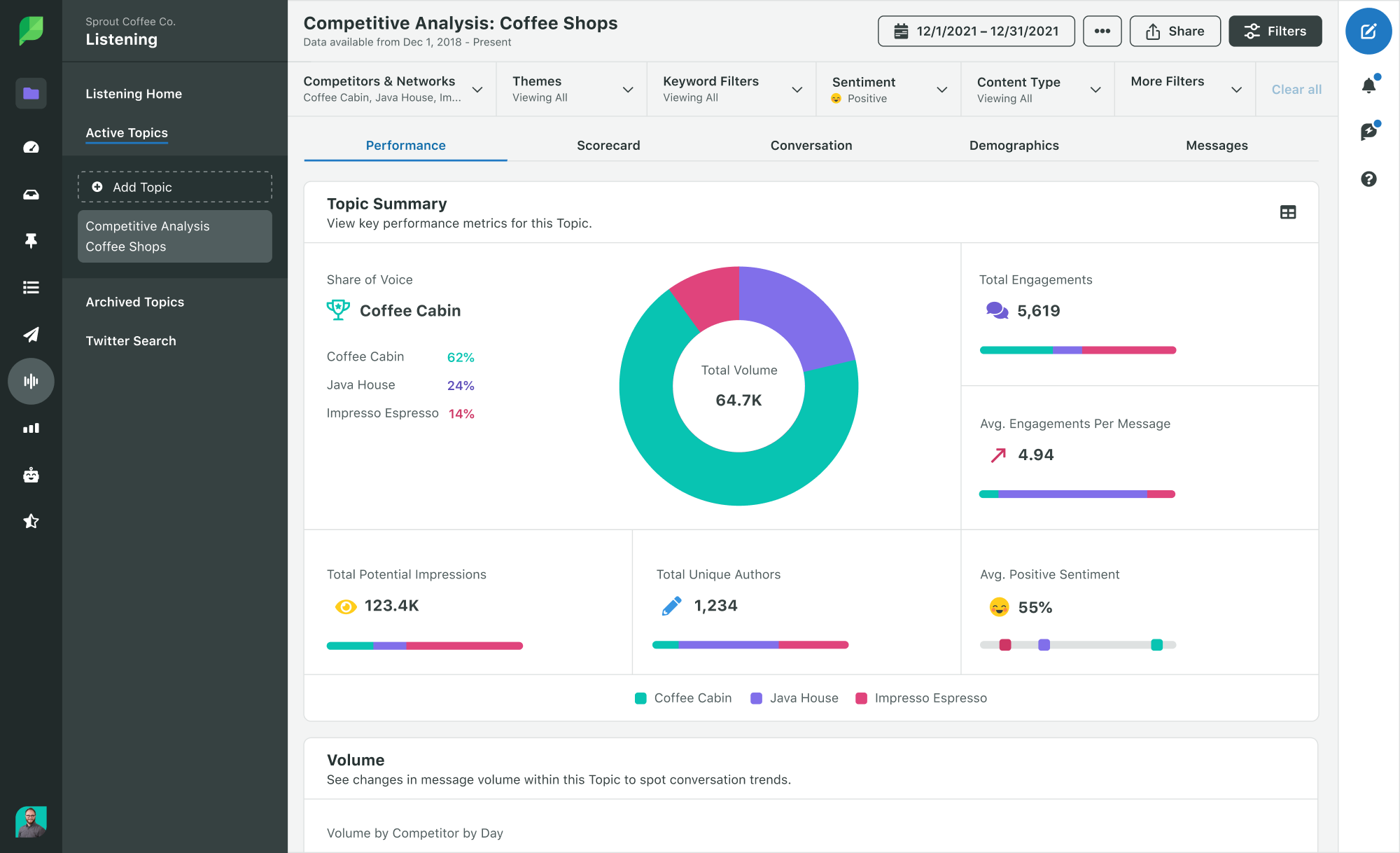
With Sprout competitive monitoring, teams can compare brand performance against competitors using metrics like share of voice, engagement, impressions and sentiment. This helps brands understand how they stack up in the market and where they may have room to grow.
Protect brand reputation with real-time sentiment tracking
Reputation can shift quickly, especially when customer complaints, news coverage or social conversations start getting wider attention. AI brand monitoring and real-time sentiment tracking help brands detect those changes as they happen.
Teams can monitor positive mentions to identify advocacy opportunities and social proof. They can also set alerts for specific keywords, campaigns or topics that may signal rising concern. When sentiment starts moving in the wrong direction, AI brand monitoring tools give brands more time to investigate, respond and share the right information internally.
Optimize business operations and improve ROI
Sentiment data shouldn’t stay in marketing. Shared with sales, product and operations, it can highlight customer needs, recurring friction points and investment priorities.
Building materials pioneer James Hardie® uses social listening sentiment to track brand health and share findings with sales and product teams. Those insights help guide strategic improvements and show how customer feedback can influence decisions beyond social.
Create engaging content
The fastest way to make content that lands is to build it around what your audience already cares about. Sentiment analysis helps teams identify the topics, questions and conversations that spark positive reactions or recurring engagement.
Brands can use those insights to create content that speaks directly to customer interests, concerns and preferences. The NBA’s Atlanta Hawks use Sprout to track fans’ evolving tastes and sentiment toward the team. In three months, they grew video views by 127.1% and their Facebook audience by 170.1%.
Nurture employee advocacy
Sentiment analysis can also show which content resonates most with your audience. That helps teams identify strong posts, customer stories and brand messages employees may want to share.
Employee advocacy works best when people have relevant, timely content to distribute. Medallia uses Sprout to automatically deliver impactful content to its employee advocates, helping extend reach through trusted voices.
Where does sentiment analysis data come from?
Sentiment analysis data comes from anywhere customers share opinions. That includes social posts, reviews, surveys, support conversations, forums and news coverage. Together, these sources help brands understand what people think, how they feel and where sentiment is changing.
Social media conversations
Social media is often where people share feedback in the moment. Across X, Facebook, Instagram, TikTok and LinkedIn, customers react to brand content, product experiences, service interactions and industry conversations.
These conversations can reveal fast-moving shifts in customer sentiment. With Sprout, sentiment from social networks can be monitored in one place, helping teams track the larger conversation without jumping between platforms.
H3: Customer reviews and forums
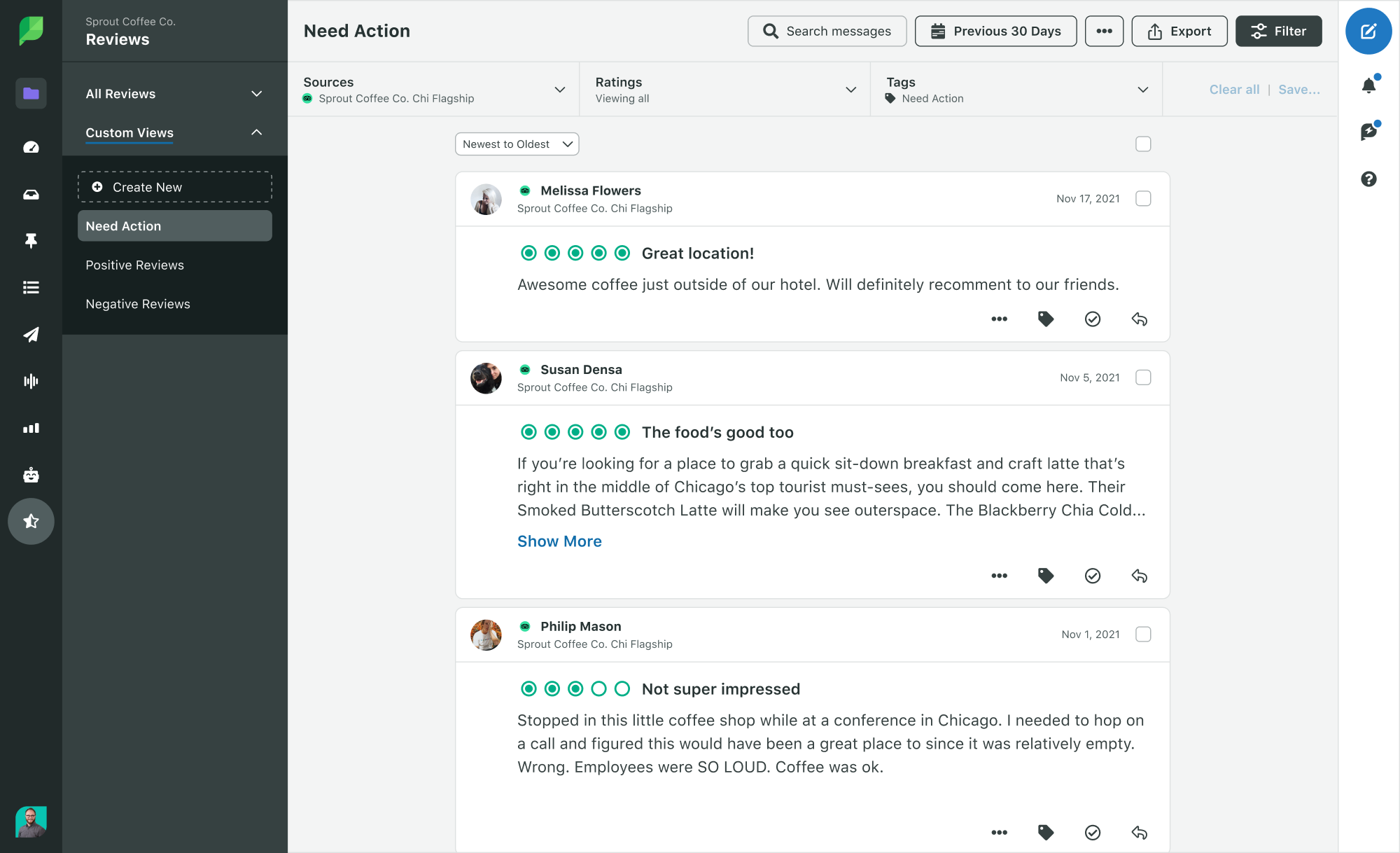
Reviews and forums give customers more space to explain what they like, dislike and want changed. Reputation and review insights from sites like Google Business Profile, Yelp, Tripadvisor and Glassdoor, along with community forums like Reddit, can reveal detailed opinions that reflect brand health.
Review sentiment can help brands identify recurring praise, repeated complaints and customer experience issues that may not show up in social comments alone. Sprout brings review management into the same workflow, helping teams reply faster, identify repeat issues and manage reviews at scale.
Surveys, support tickets and CRM data
Not all sentiment is public. Surveys, NPS and CSAT responses, support tickets, emails and live chat transcripts capture how customers feel in direct, first-party conversations.
This feedback is especially useful because it often connects sentiment to a known customer, account or stage in the customer journey. With Sprout’s Salesforce integration, customer care data can connect to the customer record, helping teams understand the issue and the relationship behind it.
News and media
News articles, press releases, broadcast segments, podcasts and industry coverage can influence public perception of a brand. Media sentiment helps teams understand how stories are shaping the larger conversation.
NewsWhip by Sprout Social tracks news and media coverage and flags growing stories, giving brands more time to monitor sentiment and respond before a narrative spreads more widely.
Challenges in sentiment analysis
Even advanced sentiment analysis has limits, mostly because people rarely communicate in plain, literal terms. Sarcasm, slang, emojis, cultural context and mixed emotions can all make sentiment harder to classify.
Here are the common challenges and how to account for them.
Understanding sarcasm, slang and context in customer conversations
Context can completely change the meaning of a message.
A backhanded compliment may read as positive. “Under the weather” looks like a comment about the forecast. A double negative like “I can’t not have my Starbucks” can flip the meaning entirely, while a phrase like “not so bad” sits in a gray area.
Comparisons add another wrinkle. Statements like “the Samsung Galaxy is bigger than the iPhone” could be positive or negative, depending on what the customer values. Emojis also carry sentiment, and tools that ignore them may miss an important part of the message.
This is why advanced sentiment analysis needs more than positive and negative word matching. It has to consider the full context of the conversation.
Managing multilingual and regional sentiment analysis
A brand’s audience rarely speaks one language. Customer comments may appear in dozens of languages, sometimes mixed within the same thread. Sentiment also does not always translate cleanly.
Tone, idioms and slang vary by region. A phrase that sounds playful in one market may read as rude or dismissive in another. Analyzing each language natively, rather than translating everything to English first, helps preserve meaning and improve accuracy.
Improving sentiment analysis accuracy with AI tools
These challenges don’t make sentiment analysis unreliable. They show why the quality of the tool matters.
Manual review is slow at scale, and human reviewers can apply judgments inconsistently. A strong AI sentiment analysis platform helps by reading context, weighing emojis, handling multiple languages and applying the same logic across large volumes of comments.
Human oversight still matters, especially for sensitive issues or ambiguous conversations. But the right tool gives teams a stronger foundation for understanding sentiment than manual review alone.
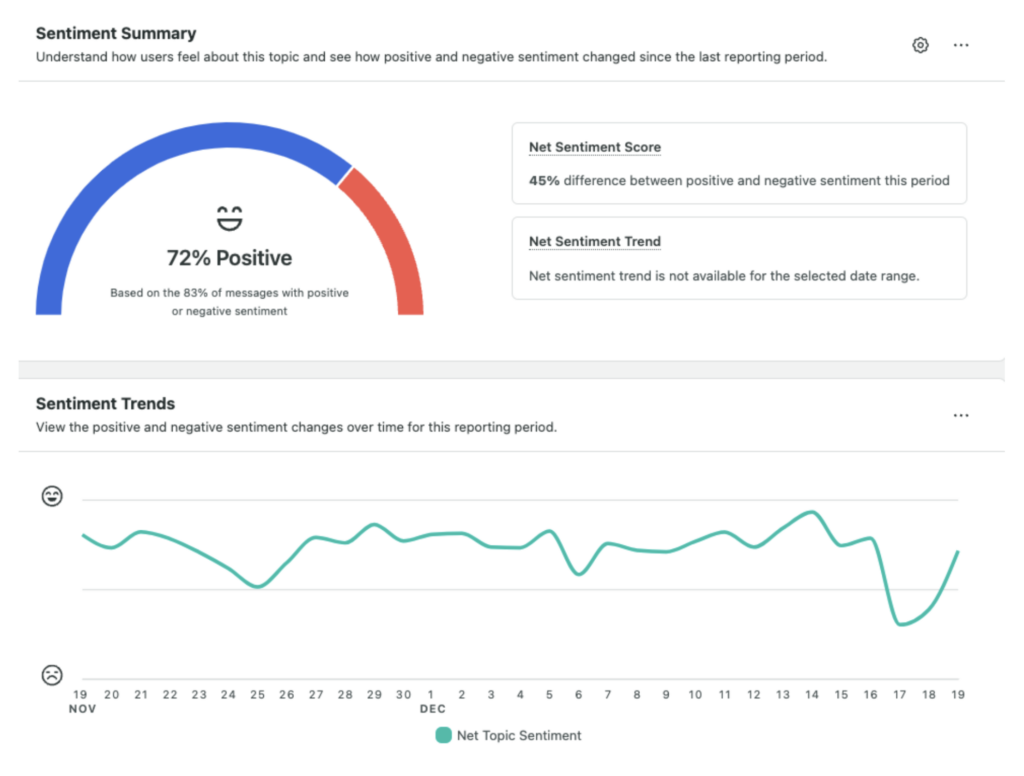
How to build a sentiment analysis strategy
A good sentiment analysis strategy turns scattered scores into clear decisions. Building one comes down to four choices: what to track, which tool to use, how to act on what you find and how to measure it over time.
Define the customer signals you want to track
Start by deciding what you need to learn. For example, if you’re measuring brand health, you’ll want to look at overall sentiment and recurring themes across brand mentions. If you’re tracking a campaign, the focus may be narrower: hashtags, campaign messages and audience response. If you’re looking for support gaps, pay closer attention to questions, complaints and negative sentiment.
The clearer the goal, the easier it is to collect the right data instead of pulling in everything and trying to make sense of it later.
Choose the right sentiment analysis tools
Look for sentiment analysis tools that can analyze customer feedback from multiple sources, account for language and cultural context, and connect sentiment trends to the broader business questions you’re trying to answer.
Sprout supports this with AI-powered sentiment analysis across social networks and the Smart Inbox, native multilingual support and listening tools that help turn social data into broader business intelligence.
Turn sentiment data into actionable insights
Sentiment data should help you understand what’s driving customer reactions, not just whether those reactions are positive or negative.
Look for patterns in what people feel, why they feel that way and where those reactions are showing up. A spike in negative sentiment may point to a service issue. Recurring praise may reveal messaging that’s resonating. Mixed reactions may show where customers need more clarity.
Use those insights to guide the next step, whether that’s adjusting your content, improving the customer experience or sharing feedback with the teams closest to the issue.
Measure sentiment trends over time
A single snapshot can show how people feel in a given moment, but it won’t tell you whether sentiment is actually improving or declining. Track sentiment over weeks and months to compare current results against your baseline.
Pay attention to sudden spikes and gradual movement. A sharp drop may point to a launch issue, service outage or negative news cycle. Steady growth may suggest that a campaign, product update or customer experience improvement is gaining traction. Repeated dips around the same topic or channel can signal a pattern, while an isolated comment or short-lived reaction may be a one-off.
Compare those shifts against key moments like launches, campaigns, product updates, policy changes and news coverage. This helps you understand what may have influenced sentiment and what, if anything, needs to change.
Turn audience sentiment into smarter marketing decisions
Customer sentiment changes quickly, but it rarely changes without signals. People share what they love, what frustrates them and what they expect from brands every day.
By tracking sentiment across social media, reviews, customer care conversations and news, brands can spot emerging risks, identify what resonates and make more informed decisions across the business.
With Sprout Social’s AI-powered sentiment analysis, teams can monitor brand health, prioritize customer care, track campaign response and turn customer conversations into action.
See sentiment analysis in action. Start your free Sprout Social trial to find the insights you need.
Additional resources for Sentiment Analysis

Top 12 sentiment analysis tools to consider in 2026
How to use sentiment analysis to analyze customer opinion
Measure brand health accurately with AI sentiment analysis


Harnessing X (Twitter) sentiment analysis for strategic business insights

Social media sentiment analysis: Benefits and guide for 2026

How to analyze customer sentiment to improve customer experience

Sentiment analysis examples: How marketers are unlocking consumer insights

How a sentiment score improves your brand strategy

The role of sentiment analysis in marketing
Share